
 BLOG
BLOG SLIDE
SLIDE EVENT
EVENT
この記事は、2024年3月7日に開催された「CyberAgent Game Conference 2024(CAGC 2024)」のセッション内容をAIによる自動文字起こしをベースに加筆修正したものになります。
セッション概要
TVアニメ『呪術廻戦』初のスマホゲーム『呪術廻戦 ファントムパレード(ファンパレ)』は、多くのユーザーに遊ばれ大量のアクセスが来ることが予想されていました。
本セッションでは、高負荷が予想される中、どのようにインフラを構築し負荷対策を行ったのか、実際のインフラ構成図をお見せしながらお話しします。
また、アプリリリース前に行った負荷試験の流れや、リリース後の負荷状況について、具体的なメトリクスの数字をお見せしながらご紹介します。
登壇内容
タイトル

自己紹介

今回発表をさせていただくのはファントムパレードのSREチームに所属しております、島田裕基です。
経歴としては2012年にサイバーエージェントに入社し、そこからゲーム事業に携わり、ゲームの開発・運用・改善を担当してきました。
ファントムパレードでは主にCloudを駆使してインフラの構築や負荷監視を担当しております。
『呪術廻戦 ファントムパレード』とは

『呪術廻戦 ファントムパレードは、2018年より「週刊少年ジャンプ」にて連載中の芥見 下々(あくたみ げげ)氏による人気漫画を原作としたTVアニメ『呪術廻戦』を元にした、作品初のスマートフォンゲームです。
TVアニメ『呪術廻戦』の第1期の物語を追体験できるだけでなく、福岡を舞台にした『ファンパレ』オリジナルのストーリーが楽しめるコマンドバトルRPGとなっています。
アジェンダ

アジェンダは上記のとおりです。
まずはじめに『呪術廻戦 ファントムパレード』のリリース前の状況を説明させていただき、その後にインフラ構成と・負荷試験のお話をさせていただきます。
そしてリリース後の負荷状況と最適化のお話をさせていただいて、最後にまとめとさせていただきます。
前提

『呪術廻戦 ファントムパレード』は2023年11月21日にリリースしました。
今回の発表はそのリリース前の負荷試験からリリース後1ヶ月経過した時点までのお話になります。
ユーザ規模とアクセス負荷の見積もり

今回は大人気タイトルということでリリース時300万DAUに耐えうるインフラが必要という要件がありました。
その要件を過去タイトルの実績により算出しています。
APIサーバのRPSを4万5千RPSに、アセット配信サーバの最大ダウンロードbytesを400Gbpsに設定しました。
こちらの目標は、リリースの2.5ヶ月前に負荷試験で達成することができていました!
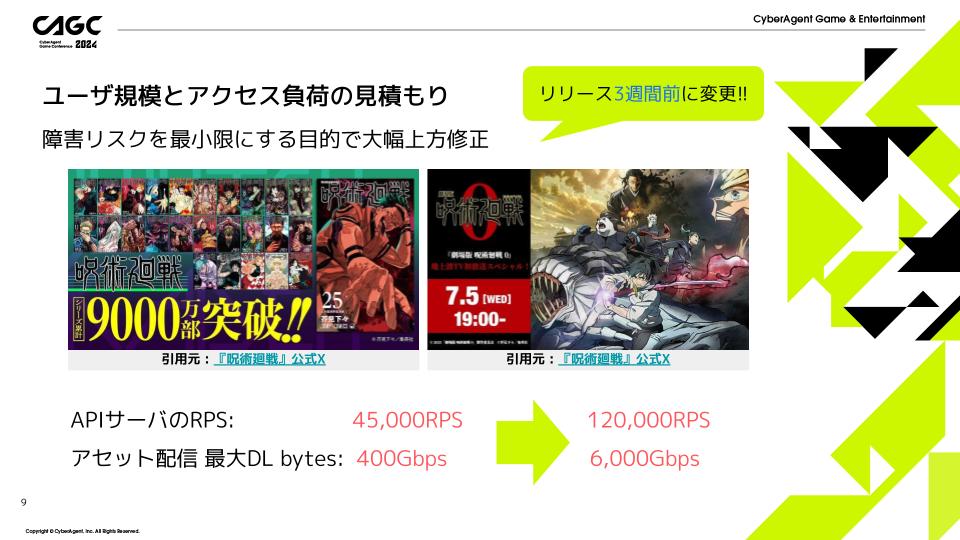
APIサーバのRPSを4万5千RPSから12万RPSに、アセット配信サーバの最大ダウンロードbytesを400Gbpsから6000Gbpsに再設定しました。
こちらの目標値を達成するようにインフラの構成と負荷試験を行っています。
簡易的なインフラ構成図
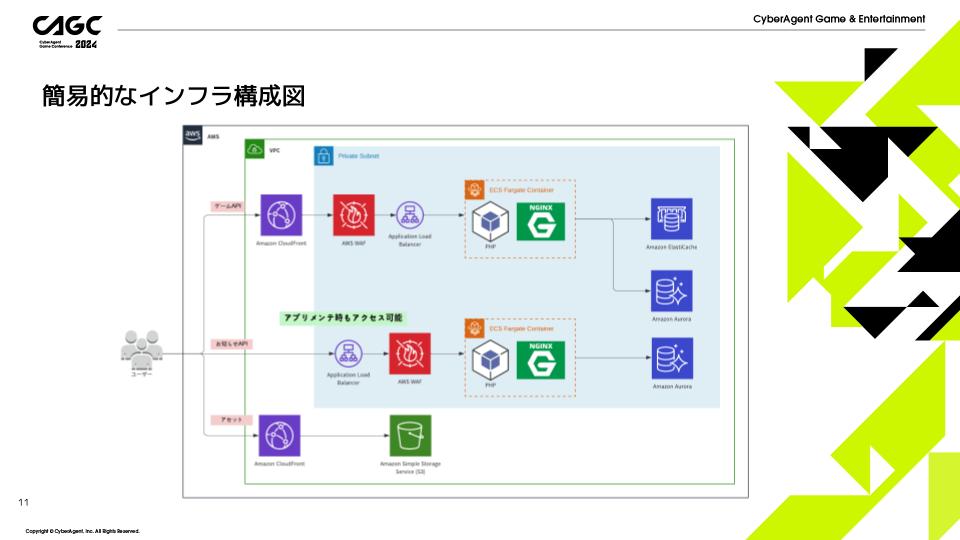
こちらがアプリケーションの簡易的な構成図となります。
大きく「ゲームAPI」「お知らせAPI」「アセット」の3要素からできています。
WebサーバにはECS Fargate、データベースにはAuroraを使用しています。
アセットのダウンロードにはS3に配置しているアセットをCloud Frontを通してアクセスしています。
インフラ構成の決定と特徴

今回はAuroraの中でも Serverless v2の使用を検討し、採用しています。
Webサーバには弊社で利用実績のあるECS Fargateを採用しました。
このインフラ構成の特徴として、ゲームAPIとお知らせAPIのエンドポイントを分けることで、メンテナンス中でもお知らせを表示・更新できる仕様にしています。
またゲームAPIの前段にCloud Frontを挟むことで、上り通信料の削減と地域制限を実現しています。
Aurora Serverless v2とは

Aurora Serverless v2とはAmazon Auroraのサーバーレス版になります。
アプリケーションの需要に応じて自動的にスケールアップ/ダウンするのが特徴で、v1よりもスムーズなスケーリングが可能です。
また、インスタンスクラスの1つとみなされるので、v1と異なり同クラスター内でプロビジョニングDBと共存が可能なのも特徴の1つです。
ただしプロビジョニングDBよりも割高なので、負荷変動が少なかったり、負荷予測が可能なアプリケーションの利用には適さないといった特徴もあります。
リソースのスペックを表すのにACUという単位が使用され、0.5~128の範囲でスケールさせることが可能です。
Aurora Serverless v2を選択した理由

まず一番大きな理由としては、リリース時の柔軟なスペック変更が可能であることが上げられます。
基本的にリリース時はかなりオーバースペックなリソースを用意しておくことが多く、こちらを素早く最適化することで不要な費用の発生を防ぐことが可能です。
次にゲームアプリケーションの特徴として深夜の時間帯は日中に比べかなりアクセスが下がるという特徴があります。
Serverless v2を使用することで、この時間帯の低アクセス時に自動でスケールダウンさせることが可能になります。
このような理由から今回Aurora Serverless v2の導入にいたりました。
ECS Fargateとは

ECS FargateとはAmazon Elastic Container Service (ECS) で動作するサーバレスなコンテナ実行環境のことです。
Fargateの特徴としてコンテナを実行するホストの管理が不要という特徴があります。
上記にスケーリング動作の図を載せております。
こちらの図のように実行するホスト自体にスケールする空きリソースがない場合、自動でホストを増やし、スケーリングできる環境を作成してくれます。
Fargate Spot
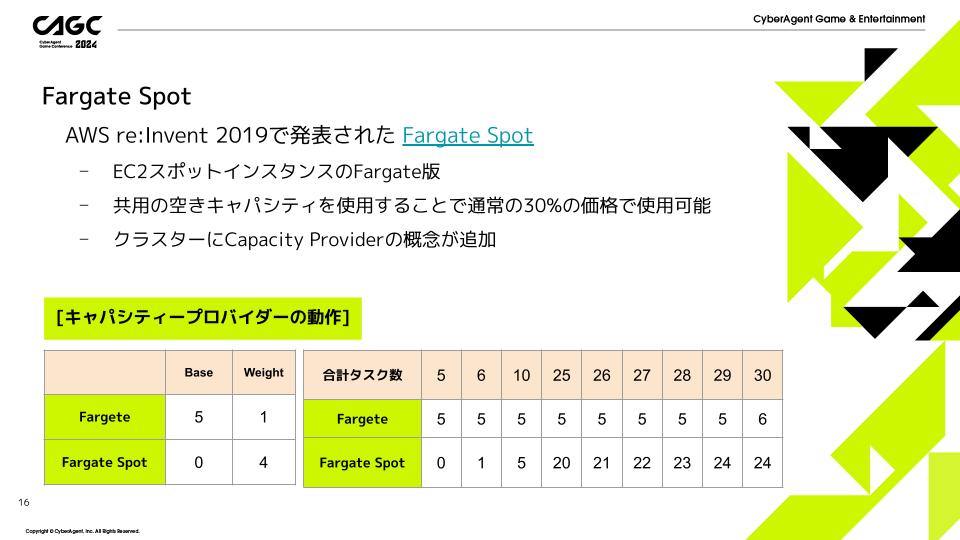
Fargate SpotとはEC2スポットインスタンスのFargate版という立ち位置で、共用の空きキャパシティを使用することで通常の30%の価格で使用可能という特徴があります。
今回このFargate Spotをとりいれることで、通常よりも費用を抑えるようにしております。
Fargate Spotの導入により、クラスターにCapacity Providerの概念が追加されています。
キャパシティープロバイダーとは簡単に言うと、FargateとFargate Spotをどのような割合で配置するかを決める概念になります。
「Base」と「Weight」を設定することでスケーリング時の実行数が決定します。
Fargate Base:5, Weight:1、Fargate Spot Base:0, Weight:4 の設定時の挙動例を載せていますので、参考にしてください。
負荷試験で確認する箇所
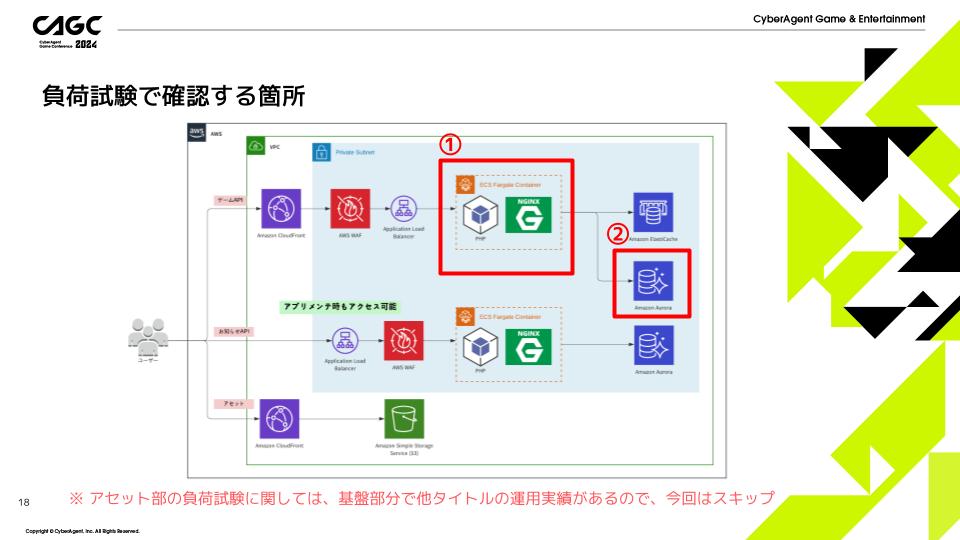
今回の負荷試験の説明では、
①Webサーバ部
②DB部
の2箇所の負荷について説明します。
アセット部の負荷試験に関しては、基盤部分で他タイトルの運用実績があるので、今回の説明からは省略します。
負荷試験の流れ

1. 目標値の設定
これは前提で説明した通り12万RPSが目標値となります。
2. ECS Fargate部分の単体での限界値測定
DB部分には十分に大きいものを使用し、Web部分にかかる負荷のみを考慮して測定します。
3. Aurora Serverless v2部分の単体での限界値測定
Web部分には十分に大きいものを使用し、DB部分にかかる負荷のみを考慮して測定します。
4. 2, 3の負荷試験をスケールアップ限界まで測定します。
5. 2, 3, 4を繰り返し、アプリケーションコードのエラー・遅い処理・データ量が多い処理・Slowqueryなどを潰します。
6. ECS Fargate, Aurora Serverless v2部分を目標値に届くまでスケールアウトします。
ECS Fargate単体での限界値測定
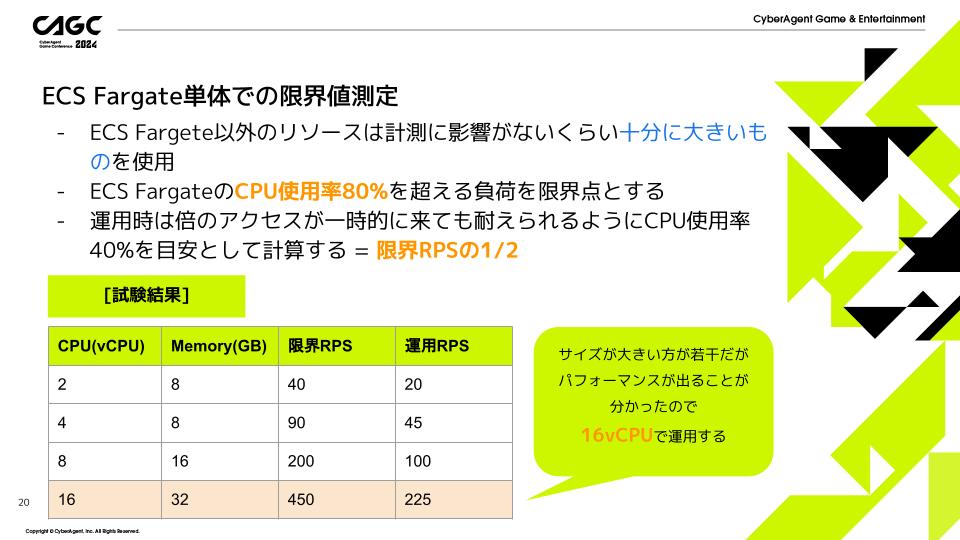
測定の条件として、ECS FargateのCPU使用率80%を超える負荷を限界点とし、運用時は倍のアクセスが一時的に来ても耐えられるようにCPU使用率40%を目安として計算します。
試験の結果は上の表のようになっています。
vCPU: 16、Memory: 32GBで1タスク225RPSが出る計算になります。
Aurora Serverless v2単体での限界値測定
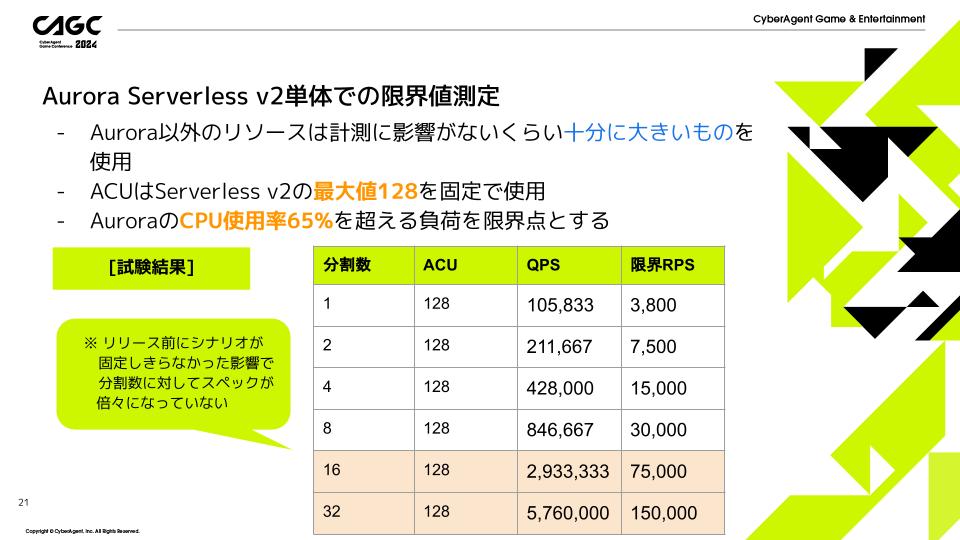
測定の条件として、ACUはServerless v2の最大値128を固定で使用し、AuroraのCPU使用率65%を超える負荷を限界点としています。
試験の結果は上の表のようになっています。
ACU128で分割数32にすることで目標の12万RPSを超える15万RPSまで出ることを確認できました。
負荷試験の結果
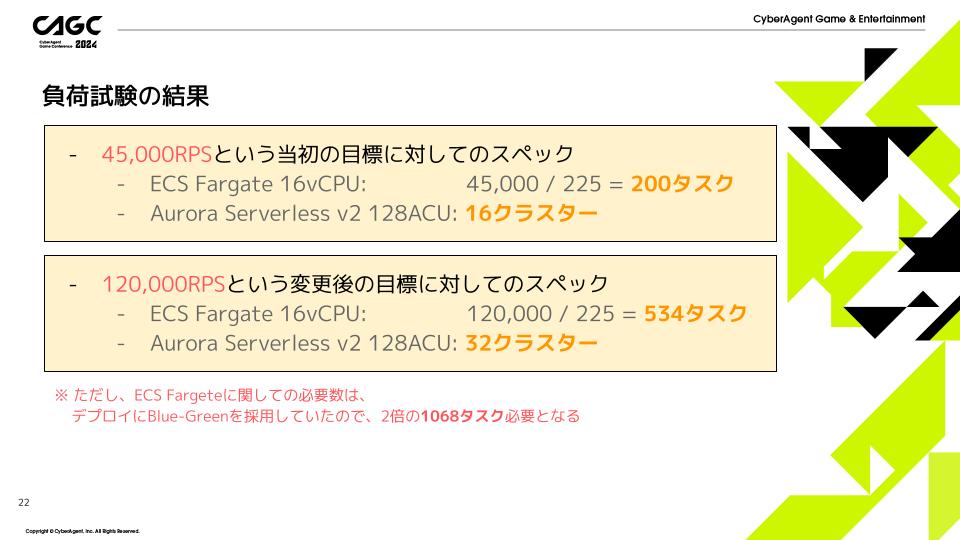
当初の目標であった4万5千RPSを達成するためには
- ECS Fargate 16vCPUが200タスク
- Aurora Serverless v2 128ACU: 16クラスター
必要であることが分かりました。
さらに変更後の目標である12万RPSを達成するためには
- ECS Fargate 16vCPUが534タスク
- Aurora Serverless v2 128ACU: 32クラスター
必要であることが分かりました。
ただし、ECS Fargateに関してはデプロイにBlue-Green方式を採用していたので、実際には2倍の1068タスク必要になる計算です。
こちらのデータをもとにAWSクオータの申請をしております。
API部の主要メトリクス - ALB

まずはAPI部のメトリクスを確認していきましょう。
上のグラフがリリースから24時間のリクエスト数の推移になります。
11/21 21:57に計測された約1万7千RPSがリリース時の最大RPSでした。
負荷試験で12万RPSまで耐えられる構成にしていましたので、問題なくリクエストをさばくことができました。
アセット部の主要メトリクス

右の図はリリースから12時間のリクエスト数とデータ量の推移を表しています。
どちらもピークはリリース後10分で記録されており、リクエストは53万RPS、トラフィックは670Gbpsを計測しました。
トラフィックに関しては6000Gbpsまで申請していましたので、こちらも問題なくさばくことができました。
リソースの主要メトリクス
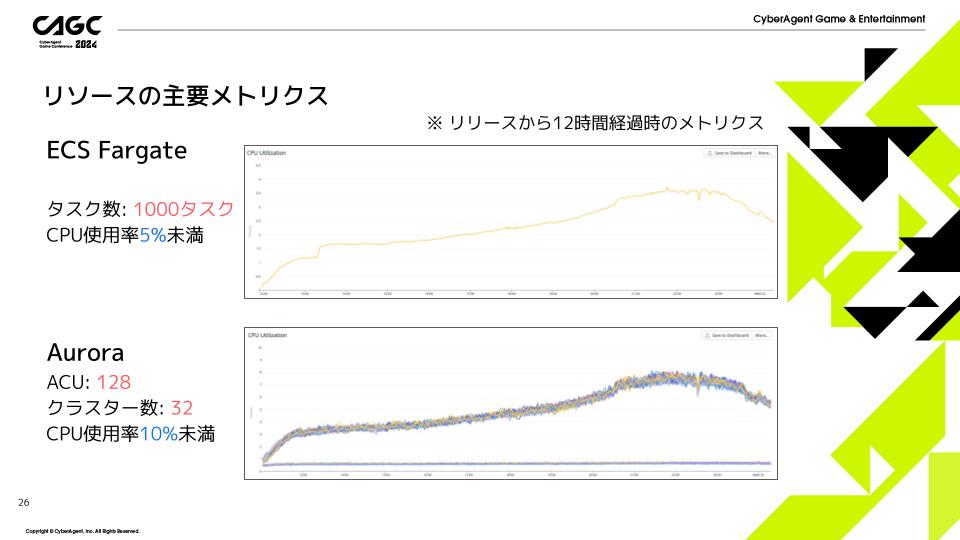
上の図はリリース後12時間のECS FargateのCPU使用率の推移で、下の図がAurora Serverless v2のCPU使用率の推移になります。
どちらもCPU使用率10%未満と余裕のある負荷であることが分かります。
リリース時の負荷状況

アプリリリース初日の負荷は、APIサーバのRPSが最大1万7千RPS、アセットサーバのトラフィックが最大670Gbpsでした。
リリース時負荷は負荷試験の目標値の1/7程度で、かなりしっかり負荷試験を行えていたので、負荷による不具合はありませんでした。
しかし、逆にリソースがかなりオーバースペックになってしまったためインフラコストが大きくなってしまうという問題点がありました。
なのでリリース後対応として、コスト削減が早急に求められることになります。
最適化の優先順位
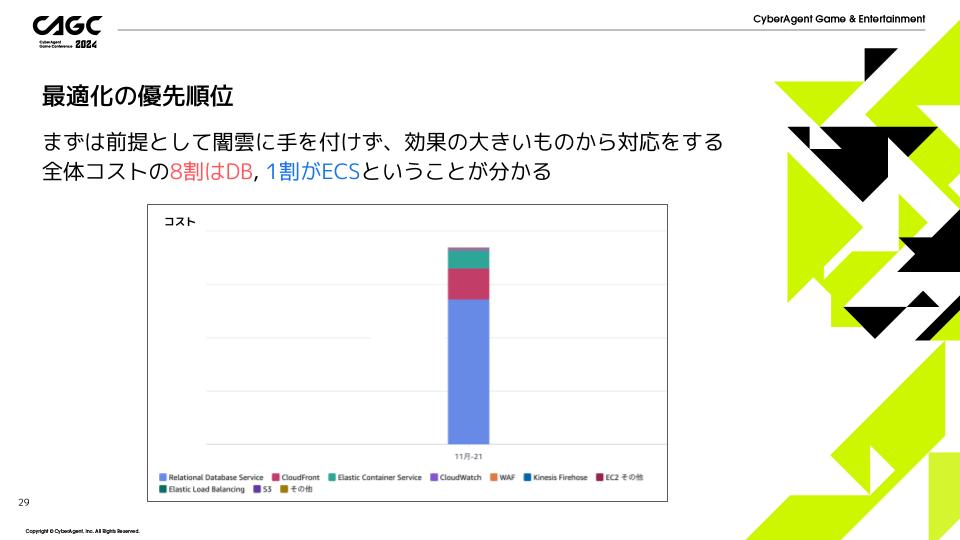
まずは最適化の前提として、闇雲に手を付けず、効果の大きいものから対応をするのが基本です。
AWSコンソールから確認したところ8割がDB、1割がECSの費用がかかっていることが分かりました。
ですのでまず割合の大きいDBの最適化から行っていくことにしました。
DBの最適化
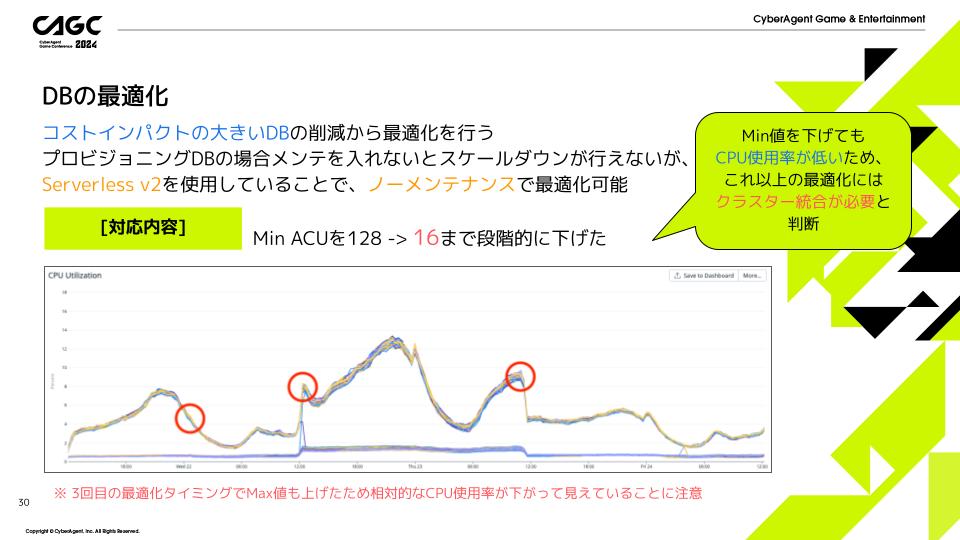
プロビジョニングDBの場合メンテを入れないとスケールダウンが行えませんが、Serverless v2を使用しているということで、ノーメンテナンスで最適化可能になります。
下の図はリリースから3日間のDBのCPU使用率の推移になります。
このグラフ上の赤丸のタイミングでServerless v2のACUに調整をいれ、128から16まで段階的に下げました。
ECSの最適化
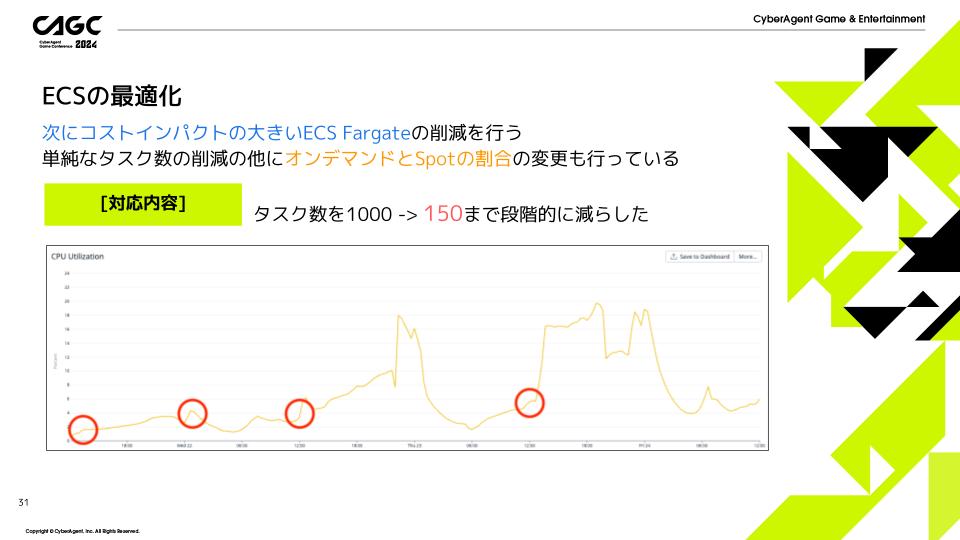
下の図はリリースから3日間のECSのCPU使用率の推移になります。
このグラフ上の赤丸のタイミングでECS Fargateのタスク数に調整をいれ、1000から150まで段階的にタスク数を減らしました。
また単純なタスク数の削減の他にFargateとFargate Spotの割合の変更も行い、費用の安いSpotの割合を増やす対応も行っています。
最適化の効果
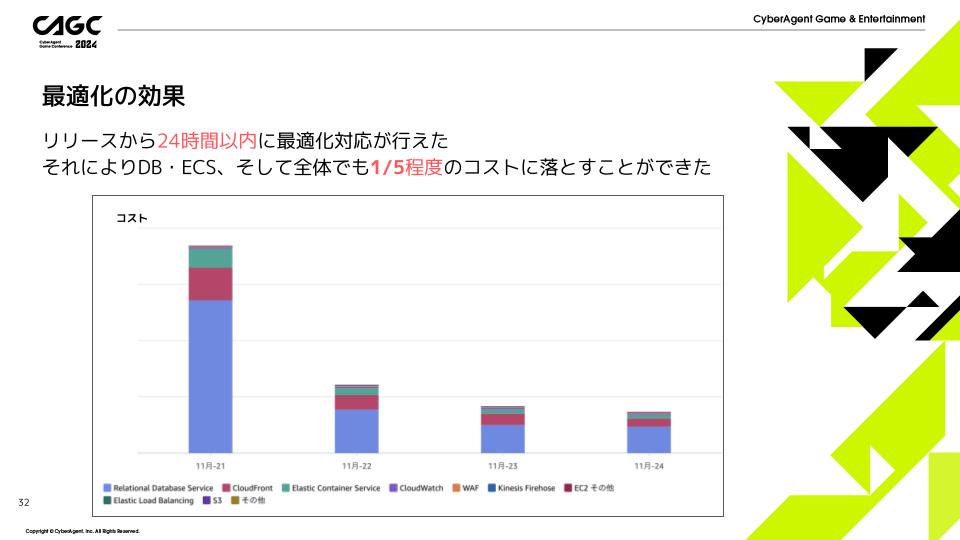
Aurora Serverless v2とECS Fargateを用いたことにより、リリース後24時間以内にインフラ費用を1/5程度まで減らすことができました。
まとめ
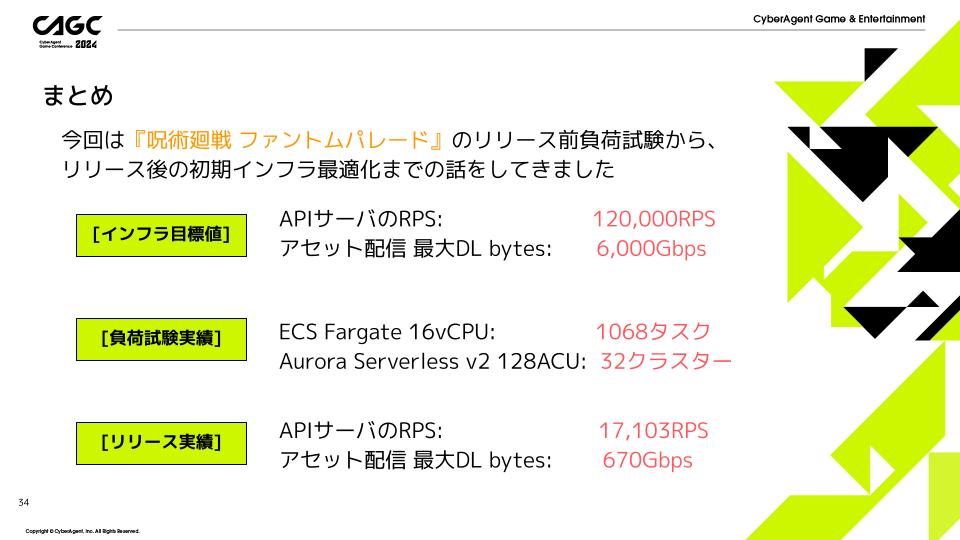
今回は『呪術廻戦 ファントムパレード』のリリース前負荷試験から、リリース後の初期インフラ最適化までの話をしてきました。
インフラの目標値としては
- APIサーバ: 12万RPS
- アセットサーバ: 6000Gbps
という大きな目標を立てました。
その目標をクリアするために負荷試験を行い、
- ECS Fargate 16vCPUを1068タスク
- Aurora Serverless v2 128ACUを32クラスター
用意することで、目標値をクリアしています。
またリリース実績は
- APIサーバの最大RPSは約1万7千RPS
- アセットの最大トラフィックは670Gbps
を計測しました。

とはいえリリース時はどれほどのアクセスになるのかを予想することは難しく、むしろ最近のアプリリリースでは余剰リソースをどれだけ早く削れるかが求められています。
今回採用した 「ECS Fargate」と「Aurora Serverless v2」は、全体の処理を止めることなくスケールを行うことができ、インフラコストをリリースから24時間以内に1/5まで削減することができました。
今回の発表は以上になります、ご清聴ありがとうございました。
©芥見下々/集英社・呪術廻戦製作委員会 ©Sumzap, Inc./TOHO CO., LTD.


