
 BLOG
BLOG SLIDE
SLIDE EVENT
EVENT
この記事は、2024年3月7日に開催された「CyberAgent Game Conference 2024(CAGC 2024)」のセッション内容をAIによる自動文字起こしをベースに加筆修正したものになります。
セッション概要
本セッションでは、スマートフォンゲーム『呪術廻戦 ファントムパレード』のマスタデータ管理について、その入力・反映・配信のプロセスを紹介します。
マスタデータの入力に関しては、開発者がストレスなくスムーズに作業できるようにするための工夫を紹介します。
マスタデータの反映・配信の基盤に関しては、ゲームを遊んでいただけている皆様がよりストレスなく楽しんでいただくためのマスタデータ基盤の設計や工夫を紹介します。
登壇内容
自己紹介

今回発表する『呪術廻戦 ファントムパレード』ではバックエンドのテックリードとして開発に従事してきました。
また実装面では基盤周りを担当することが多かったかなと思います。
『呪術廻戦 ファントムパレード』とは

今回発表する『呪術廻戦 ファントムパレード(ファンパレ)』というのは人気漫画を原作としたテレビアニメの呪術廻戦を元にしたスマートフォンゲームです。
テレビアニメの物語を追体験できるだけでなく 『ファンパレ』オリジナルのストーリーも楽しめるコマンドバトルRPGとなっております。
はじめに
はじめに本発表で説明するマスタデータとは何かを説明したいと思います。

マスタデータはゲーム内の設定値やバランスなどを格納するデータで、キャラクターや敵などのパラメータなども含まれます。
新しいキャラクタやイベントの追加のようなものもマスタデータを追加・更新することで実現することができます。
例えば下に書いてあるようにcharacter_mastersとevent_mastersの2つのマスタを用意してみました。
| マスタ名 | 説明 |
|---|---|
character_masters |
キャラクタ毎の名前や強さのパラメータを管理しています |
event_masters |
各イベントの名前と開催期間を管理しています |
本発表ではこのようなものをマスタデータと呼ぶことにします。
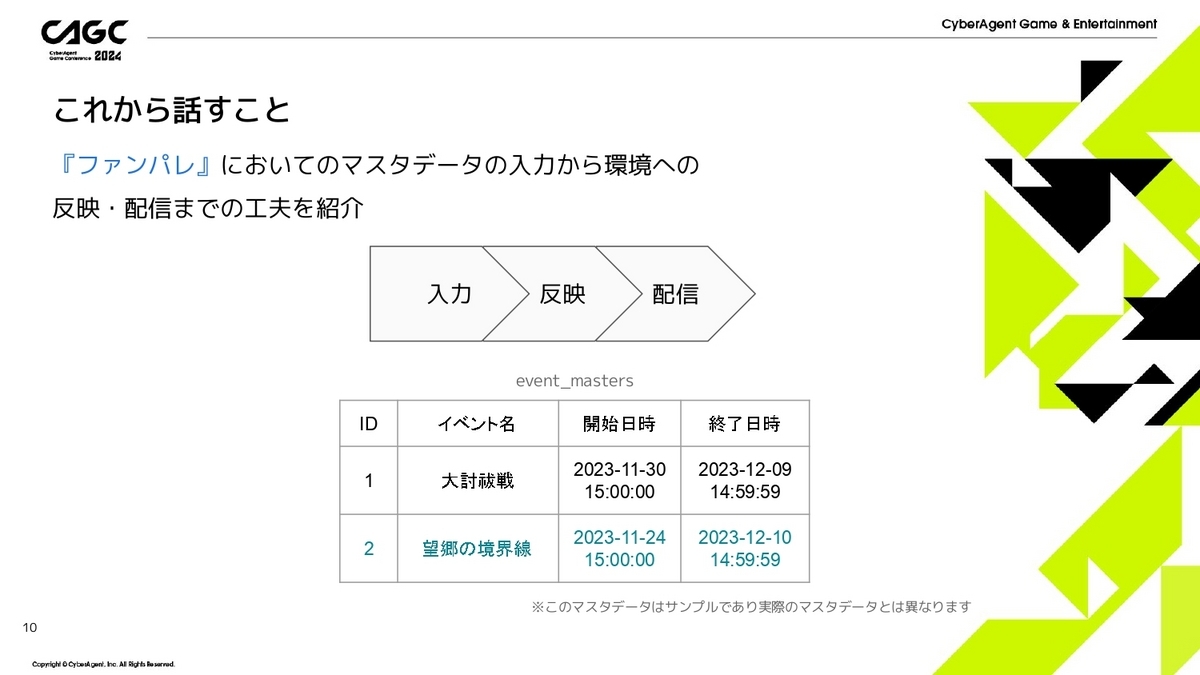
今回の発表で話すこととしては、『ファンパレ』においての「マスタデータの入力から環境への反映」、そして「クライアントへの配信」までを紹介したいと思います。
例えば、先程のevent_mastersの例で、「ID=2のイベントを追加したい」としたときのことを考えます。
ID=2のレコードのマスタの入力する、そして、動作確認をして問題なければ本番環境に反映し、サーバサイドの処理で新しいマスタデータを参照できるようにする、配信してクライアント側で新しいマスタデータを参照できるようにする、までの流れで説明したいと思います。
マスタデータの入力
はじめにマスタデータの入力の仕組みにおける設計思想について紹介します。
まず、リリースの管理やマスタデータをバージョン管理する必要があると思いますが、『ファンパレ』ではGit管理することにしました。
またGitHubを利用することで、GitHub上で反映内容の確認や差分の確認ができたり、PullRequestでダブルチェックすることも可能です。
次に、マスタ入力は、実際の本番データになるマスタデータを入力するプランナーさんやレベルデザインの方と、色んなパターンを入力してみてデバッグするQAさんがほとんどです。
すなわちエンジニアでなくても入力しやすい環境を整えてあげないといけません。
そのため、なるべくGitコマンドは使わせないようにしつつ、やったとしてもGitHubのウェブページ上でポチポチするくらいにしたいと思いました。
このような考えを元に、簡単な操作でマスタ入力・実機で動作確認、そして問題なければマージまでを非エンジニアの方でもできるようにしたいです。
こちらは、マスタ入力の大まかな流れになります。
- データの入力
- 開発環境の作成
- 開発環境への反映
- 開発環境に接続して実機で動作確認
- PR作成・レビュー・マージ
- 開発環境の削除
詳しく見ていきます。

まずはマスタデータの入力についてです。
スプレッドシートを利用してマスタデータの入力をしています。
スプレッドシートは複数人で同時に編集可能です。
また、スプレッドシート側で作業ログを残してくれていると思いますが、これを利用することで、例えばマスタデータを反映したらアプリでエラーが出るようになりましたという時にログを見れば誰がどういう作業をしたかがわかるので、容易に調査できます。
また、スプレッドシートの機能として関数やプルダウンリストだったりと色々な機能が充実していて、専用のマスタ入力ツールを作らなくても色々なことが実現できます。
それらをメリットと感じ、スプレッドシートを選択しました。

次に開発環境の作成と削除についてです。
作業単位ごとに開発環境を作れるようにしています。例えばイベント追加をするといったような作業単位で環境を作成できます。
まず、開発環境の作成ですが、Gitのブランチでfeature/dev-xxxxxのような命名規則でブランチを作成すると、ブランチ名に対応した名前の環境が作成されます。
次に環境の削除についてです。
これは、作成したブランチfeature/dev-xxxxxを削除するだけで環境も削除されるようになっています。
ということは、ブランチの作成と削除のみなので、これってGitHubのウェブページ上でできてしまうのです。なのでGitコマンドが不要になります。

次に開発環境へのマスタデータの反映についてです。
これは、Slackからデプロイコマンドを実行して反映します。
コマンドを実行するときに指定することとしては、
- どのマスタを反映させるか
- どのマスタバージョンまでのデータを反映させるか
- どの環境に反映させるか
です。
また、デプロイの処理の内容についてですが、
- スプレッドシートからマスタデータを取得してきます
- その内容を開発環境に反映させます(ここは後で詳しく説明します)
- その反映処理と並列してマスタデータのバリデーションチェックを行います
- そして、作業ブランチにコミットしてあげます
では、それぞれについては詳しく説明していきます。

1つ目です。
スプレッドシートに入力されているマスタデータをCSVファイルとしてダウンロードします。
このとき、Google Apps Script(GAS)は使わない方針にしました。
過去の経験からもスプレッドシート毎にGASを作成すると壊れる可能性もあったり、スクリプトの管理が大変なので今回は使わないようにしました。
そこで、スプレッドシートではなく、外部でプログラムを用意して、GoogleスプレッドシートAPIを利用して、入力したデータを出力するようにしました。

また、ダウンロードするマスタの指定方法についてですが、例えば、この左下のようにイベントマスタシートにevent_mastersとevent_item_masters等のイベントに関連するマスタが入力されているとします。
これとはまた別に右のスプレッドシートのように、「ダウンロードリスト」というものがあり、そこでは、どのスプレッドシート(どのマスタデータ)のものを反映させるかを制御しています。
ダウンロードリスト上でチェックを入れたり外したりすることで、反映したいマスタを指定することができます。
このダウンロードリストの例だとチェックが入っているカード関連とイベントマスタ関連のスプレッドシートの内容をダウンロードするという指定になります。
こうすることで、デプロイコマンドを実行したら、イベントマスタにチェック入れているので、それに対応するevent_mastersやevent_item_mastersがダウンロードされ反映されるということになります。
ダウンロードリストは複数パターン用意でき、例えば、イベントの追加をしたいときは、イベントのマスタや一緒にカードが追加される運用であればカードもチェックしておけば、イベントの更新ごとにそのダウンロードリストを使い回すことが可能になります。
なのでこの複数あるダウンロードリストってのは作業単位だったり、更新内容単位で分けることができます。
Slackから「どのマスタをダウンロードするかの指定」というのは、どのダウンロードリストを利用するかの指定になります。
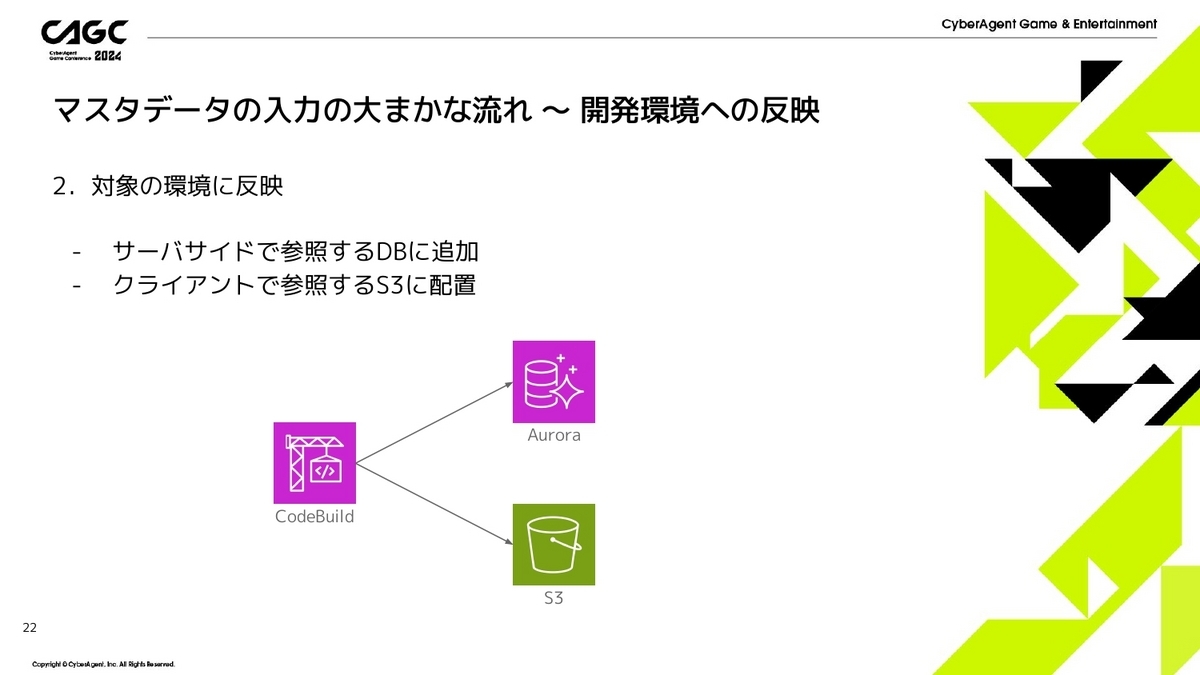
次に対象の環境に反映です。
サーバサイドのロジックから参照するデータベースや、クライアントがダウンロードするために事前にS3にアップロードします。
ここについては後ほど説明したいと思います。

開発環境への反映と並列して、マスタデータのバリデーションチェックを行います。
バリデーション結果、問題があればSlackに投稿されます。
デプロイの結果もSlackに投稿するようにしているのですが、マスタ入力者は基本的にSlackを使っていればマスタの更新ができる仕組みになっています。

マスタデータのダウンロードと開発環境への反映ができたら、対応する環境の作業ブランチにCI側でコミットしてあげます。
こうすることでマスタ入力者はGit操作をせずにマスタデータをコミットすることができます。

環境の準備が整ったら実際にアプリで動作確認して問題なければPRを作成し、レビューしてもらいマージしていきます。
最後にブランチを削除することで、環境も削除され、作業終わりです。

マスタ入力のまとめになります。
実際のマスタ入力者の方々からは、スプレッドシートの操作とSlackを触るくらいなので、作業自体はシンプルだし、新規入場者の方にも教えやすいという声もいただいてます。
「なぜか入力中にアプリが動かなくなった」みたいな問題が起きても、Slackのログからその人がどのマスタを反映したのか、とか、あとはスプレッドシートの履歴やGitのコミットログからどういうマスタを反映したかがわかるので、調査がしやすく、すぐに解決できることが多いです。
また、はじめの設計思想で説明したように、エンジニアが作業に関わらないのでエンジニアの工数も取られず、問題があってもほとんどはバリデーションエラーの内容を見て自己解決していただけるので、スムーズにマスタ入力ができる環境が整ったと思います。
マスタデータの環境への反映と配信
次マスタデータの環境への反映と配信になります。
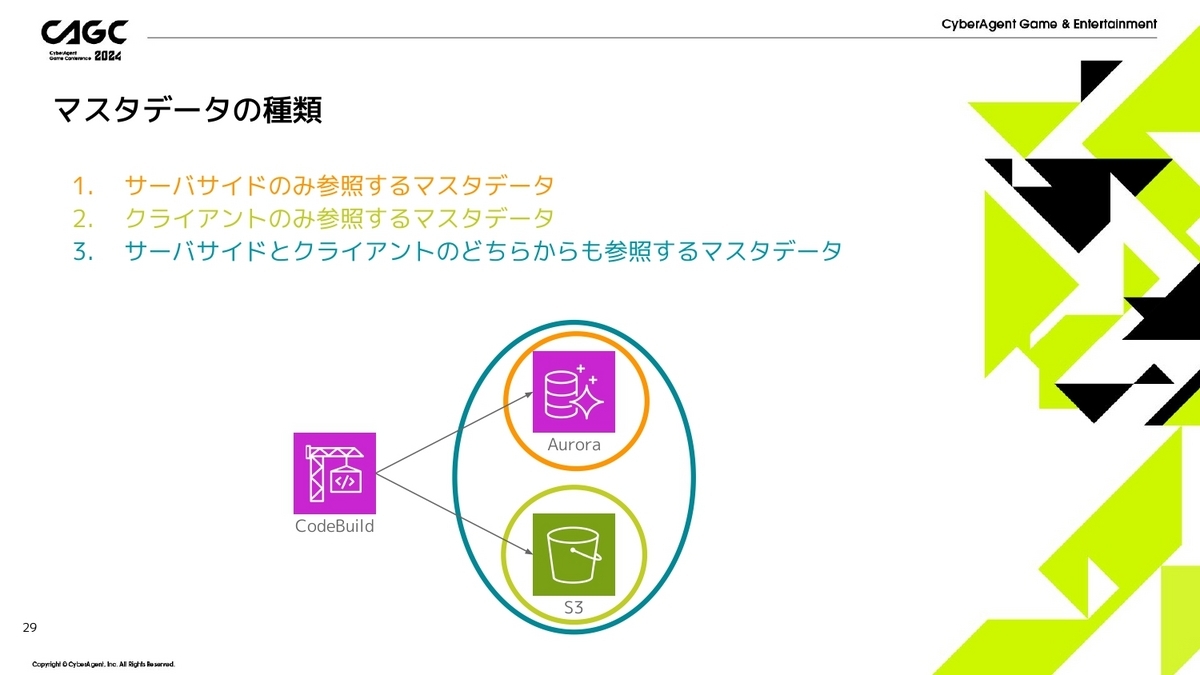
マスタデータの反映・配信の話をする前に事前にマスタデータの種類を紹介したいと思います。
『ファンパレ』においてのマスタデータは大きく3種類のものがあります。
- ユーザ様に見せないようなパラメータ等を設定したサーバサイドでしか使わないマスタデータ(これはデータベースのみにしか反映しません)
- 演出や表示の制御などに使うようなクライアント側でしか使わないマスタデータ(これはS3のみにしか反映しません)
- サーバサイドとクライアントどちらでも使うマスタデータ(例えばイベントの期間情報はサーバサイドでチェックする必要もありますし、クライアント側でイベント期間を表示する必要があるので、どちらでも使う必要があります、こういうのはデータベースとS3どちらにも反映します)

マスタデータの反映と配信の設計思想になります。
まず、サムザップの過去のプロジェクトの課題としまして、APIサーバからマスタデータをクライアントに返すということをしてました。
これは、APIサーバの負荷にもなるし、マスタデータってのは静的なデータになるので、S3に配置してCDNを介してあげれば良いかなと考えました。
また、同じマスタデータを何度もダウンロードしてしまっていたので、変更がない場合は再ダウンロードさせない仕組みにすることで、ユーザ様の端末のデータ通信量をなるべく少なくしてあげたいなと思いました。
複数のマスタデータを並列ダウンロードすることで、ダウンロード画面での待ち時間をなるべく減らし、ストレスなく楽しめる状態を提供したいなと考えました。

工夫していることについて、2つ紹介したいと思います。
テキストマスタとマスタのグルーピングについてです。

まずはテキストマスタについてです。
これはマスタデータのテキスト部分についてで、テキスト部分ってクライアント側でユーザ様に見せるデータだと思うのですが、ここの情報というのはサーバサイドでは使わないことがほとんどかなと思います。
そういったテキスト部分を分離してあげることで、サーバサイドとしてはマスタデータを最小限の情報だけで扱うことができるようになります。
また、分離したテキスト部分を別の言語に差し替えてあげることで、多言語対応も可能になるかなと思います。
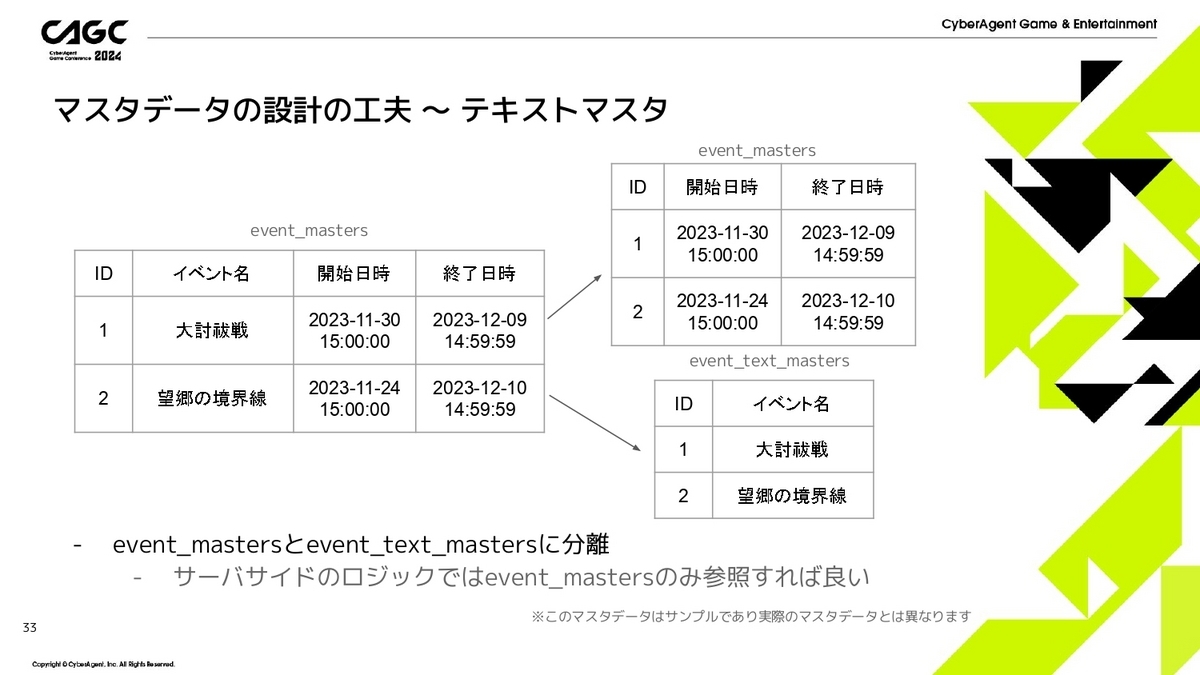
次にテキストマスタの実際の例になります。
先程のevent_mastersの例だと、開始日時と終了日時はサーバサイドでも使うのですが、イベント名っていうのはサーバサイドでは使わないので、ここの部分を分離してあげようということです。
そこで、右のようにevent_mastersには開催期間を、event_text_mastersにはイベント名を用意してあげることで、テキスト部分の分離ができます。
こうすることで、サーバサイドのロジックとしてはevent_mastersだけを参照すれば良いことになります。

次にマスタのグルーピングについてです。
いくつかのマスタをグルーピングして、1つのファイルに結合し、S3にアップロードするという仕組みになります。
そのグルーピングの話なのですが、1マスタ1ファイルにしてしまうと結構なファイル数になって、マスタデータのダウンロード時のネットワークの接続コストが多くなってしまうと思うので、適度に結合してあげてファイル数を減らしてあげることで、ネットワークの接続コストを減らしてあげるという目的があります。
なので、1つのグループというのは、なるべく同じアップデートで一緒に更新されるものが良いかなと思っております。
例えばevent_mastersとevent_text_mastersというのは、さっきの例だとイベントが追加されるとどちらもレコードを追加する必要があるので、どちらもダウンロードする必要があります。
それに対して、右のようにプレイヤーレベルに応じてパラメータが変わるようなplayer_level_mastersがあったとして、それを同じグループにしたとすると、イベントが追加されるたびに関係ないこのplayer_level_mastersがダウンロードされてしまうみたいなことになってしまいます。
そのため、なるべく同じタイミングで更新されるものを同じグループにする工夫もしています。
では、マスタを環境に反映して、それをクライアントに配信するまでの話をしていきたいと思います。
まず、マスタバージョンを時限で切替るために、切り替えの前後に、古いマスタと新しいマスタどちらも取得できる状態にしないといけません。
そのため、事前にS3にそれぞれのバージョンをアップロードしておく必要があります。
そして、ユーザ様がアクセスした時点のバージョンのマスタデータを取得できるような仕組みにする必要があります。
同じマスタファイルに対して複数のバージョン管理ができるように、今回はS3のバージョニング機能を利用しました。
こうすることで、ファイルごとのバージョン管理というのをAWS側に任せちゃいます。
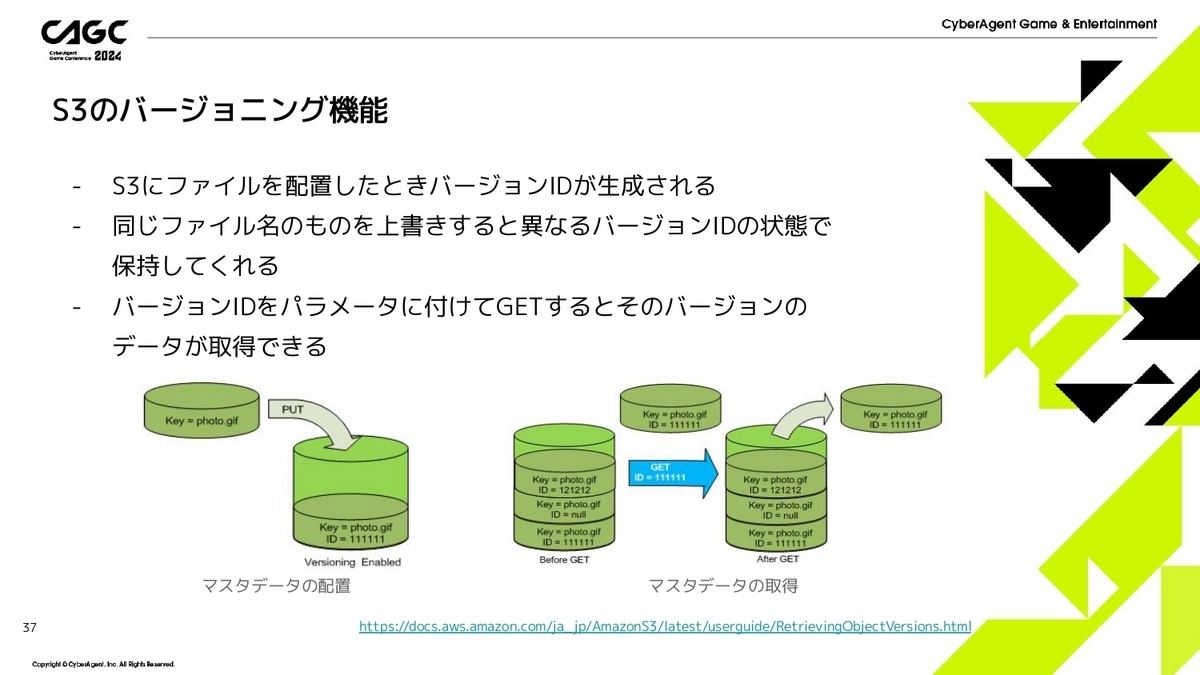
S3のバージョニング機能で今回利用しているところを軽く説明したいと思います。
S3のバージョニングを有効にすると、ファイルを配置したときにバージョンIDが生成されます。
同じファイル名で上書きしても、また異なるバージョンIDが生成されます。
その生成されたバージョンIDをクエリパラメータについてGETするとその時にアップロードしたファイルが取れるというものになります。
下の図の例だと、バージョンIDが111111のときのファイルが取得したいって場合は、クエリパラメータに111111をつけてリクエストすると、その時のphoto.gifが取得できます。
このような機能を利用して、バージョンごとのマスタデータの取得を実現しました。
では、実際にマスタを環境に反映させる処理について説明します。
なお、説明のために紹介する処理は実際のものよりシンプルにさせたり、一部変えて説明させていただきます。
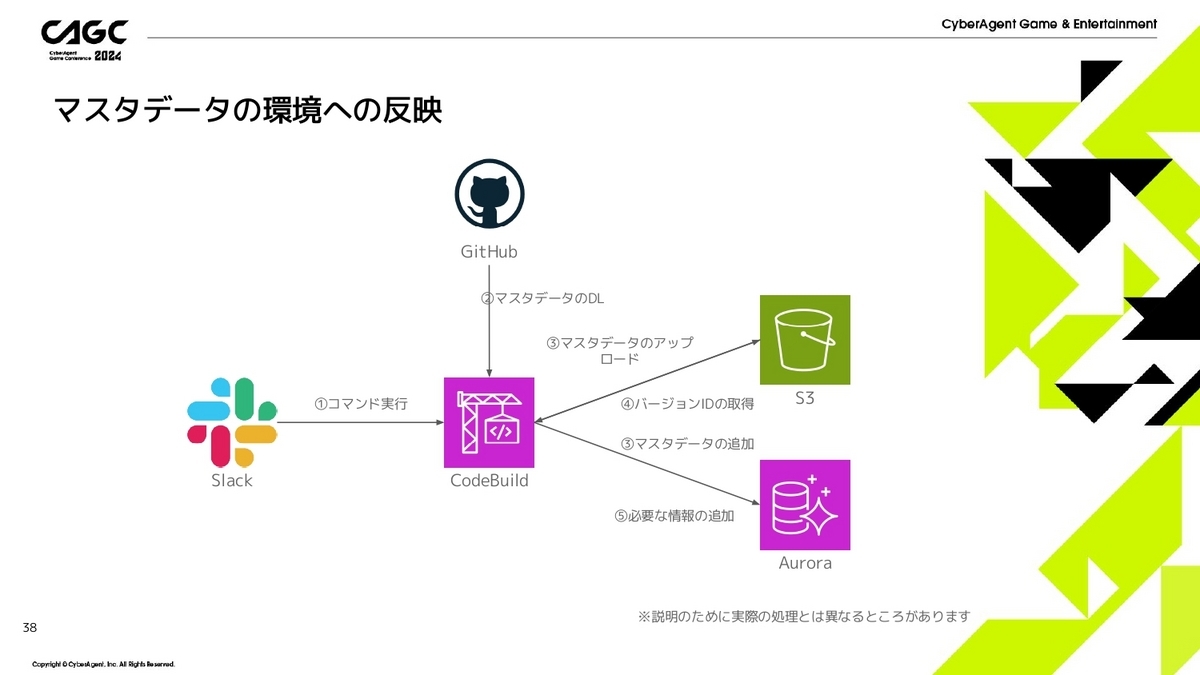
- Slackからコマンドの実行をします。
- GitHubからマスターデータをダウンロードしてきます。
- 各バージョン毎の各マスタデータをクライアントがダウンロードできるようにS3にアップロードします。このときに事前にグルーピングしたり、圧縮、暗号化、難読化等の処理を実行します。また、サーバサイドのロジックで扱えるように、データベースにも入れておきます。
- S3に配置したときにファイルごとにバージョンIDが生成されます。
- 各バージョン毎の各ファイルごとに生成されたバージョンID等の情報をデータベースに保存しておきます。
このようにして環境への反映をしていきます。
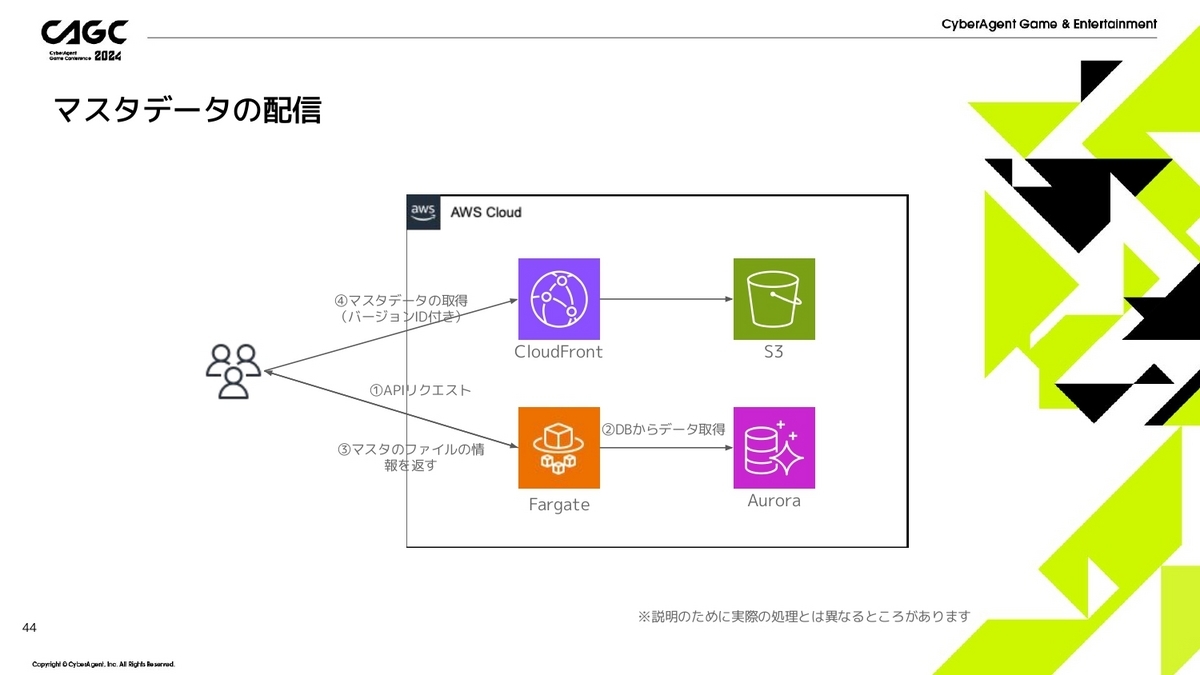
そして、S3にアップロードしたファイルをクライアントから取得しにいきます。
- まず、APIサーバにリクエストを投げます。
- データベースから現在のマスタバージョンで利用するマスタデータの一覧情報を取得します。
- マスタデータのグループの一覧、すなわちS3に配置されているファイルの一覧を返します。このとき、S3にリクエストを投げるときに必要なバージョンIDもセットで返してあげます。また、ファイルごとのハッシュ値も求めて返してあげることで、マスタデータに変更があるかをクライアントが検出できるようになります。
- サーバから返されたハッシュ値とクライアント側でダウンロード済みのマスタデータのハッシュ値が異なる場合、再度ダウンロードが必要になるので、APIサーバから取得したファイル名とバージョンIDを利用してS3からダウンロードしてきます。
このようにしてマスタデータの配信をしていきます。

マスタデータの反映と配信のまとめです。
マスタデータはCDNを利用してS3から配信されるので、運用中に負荷をあまり意識しなくても良い作りにできたなと感じております。
また、並列ダウンロードも実現でき、導入時ではありますが、ダウンロード速度が早く感じました。
そして、一部機能をAWS側に任せたりすることで、バージョンごとの反映と配信の構成はシンプルにできたんじゃないかなと思っております。

以上で発表を終わりにします。ご清聴ありがとうございました。
※発表で紹介したマスタデータはサンプルであり実際のマスタデータとは異なります
©芥見下々/集英社・呪術廻戦製作委員会 ©Sumzap, Inc./TOHO CO., LTD.


